

Distinct combination selection
I have a need to determine the distinct number of combinations of selections in a fantasy competition – where the competition is to guess the final ladder of a sporting league. Participants order their selection based on who they think will come first, second, third, etc.
It got me thinking… how can I get a distinct count of records grouped by PlayerID with multiple rows? Picture the following: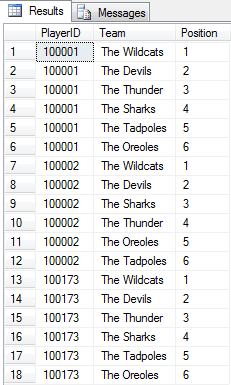
You can easily see here that PlayerID 100001 and 100173 have the exact same selection. Assuming there are hundreds of entries (which I’ve omitted on purpose), I want to return a list of selections and how many players have picked that selection.
There are many ways to skin a cat, but making use of STUFF and FOR XML I can generate a concatenated list of selections and then perform a simple count from there. For the purposes of this example, I am going to divide the query up into pieces with #temp tables, though it could easily be returned with one sub-query.
First, collect the players and concatenate their selections making sure to order by position so they’re populated in the correct order of selection.
SELECT p1.PlayerID,
STUFF( (SELECT ','+Team
FROM ladder p2
WHERE p2.PlayerID = p1.PlayerID
ORDER BY Position
FOR XML PATH(''), TYPE).value('.', 'VARCHAR(MAX)')
,1,1,'')
AS Selection
INTO #selections
FROM ladder p1
GROUP BY PlayerID
SELECT * FROM #selectionsThis will return a result set like the following:
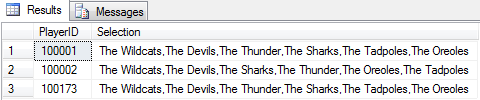
Which we can now easily query the counts of distinct selection. Like so:
SELECT Selection, COUNT(Selection) thecount
FROM #selections
GROUP BY Selection
HAVING (COUNT(Selection) >= 1)
-- change to >1 if you don't care about unique selection
ORDER BY COUNT(Selection) DESCDelivering the desired result like the following:

I trust this assists someone and, if time permitted, gets me thinking about other ways to achieve the same outcome.


Leave a comment